Proton
慢即是快。
去中心化。
现在我们在 Actor 模型中设计一个去中心化社交媒体。
我叫它 Proton 。我们面向未来设计。

互联网计算机(IC)是底层设计成去中心化的云服务,底层去中心化就代表:我们部署的网站服务、智能合约 但是如果违背了全社区的意愿,并引起公愤,可能被 DAO 投票关掉 不会被某些人随意关掉。
上层部署的应用可以由我们自己掌控,储存自己的私人数据。也可以选择通过 DAO 来控制,变成完全去中心化的 DApp ,社区自治。
IC 的智能合约是一种 Wasm 容器,叫 Canister ,类似于云服务的小型服务器,功能强大,可以直接提供计算、储存、托管网页、HTTP 外调(预言机)、WebSocket 等服务。
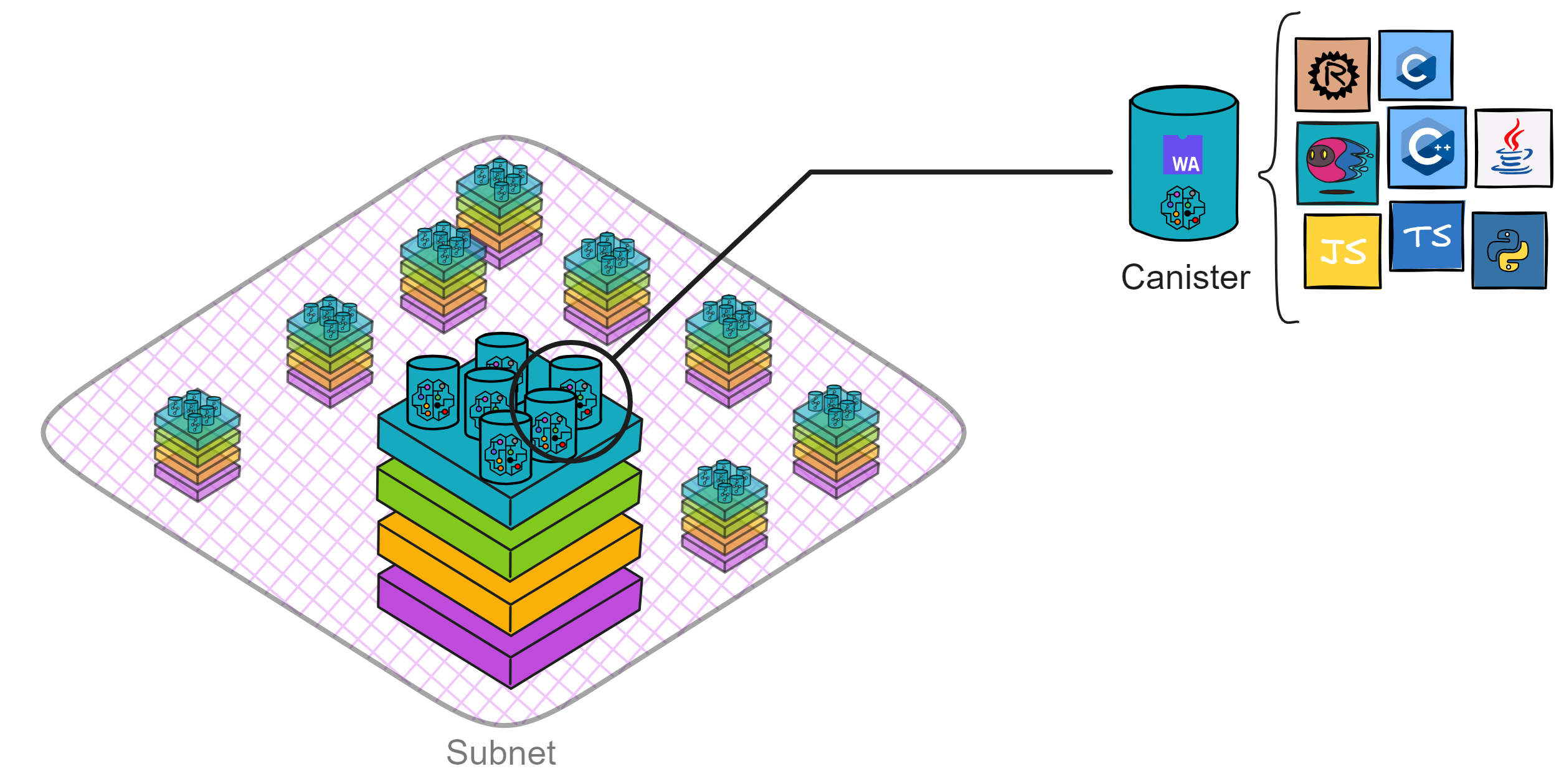
Canister 通过 Motoko 或 Rust 实现了 Actor 编程模型,我们首先需要理解 Actor 模型的基本原理。Actor 模型是一种并发计算模型,它通过消息传递和异步处理来实现并行和分布式计算。
所以在设计 DApp 时,应该让每个 Canister 负责不同的功能模块。比如一部分 Canister 负责记录用户资料、一部分 Canister 负责存储帖子。
另外,还要注重 Canister 的可扩展性,我们可以动态创建同一种 Canister 应对高负载的情况。
设计理念
我们要构建一个真正开放的 Web3 DApp ,它是基于 Actor 模型的模块化数据主权。
我们希望每个用户都有自己独立的空间(Feed Canister),完全由自己掌控。用户只要跟自己的 Canister 交互就行,后续的推送都由 Canister 们协作慢慢自动完成。
用户甚至可以直接用代码中部署自己独立的 Feed Canister 与 Proton 交互。(这做起来很麻烦,只适合程序员用户,他们可以为容器开发高级自定义功能)这允许社区创建自定义高级功能。
Feed 是每个人的服务终端,人们可以随意切换自己的 Feed 和前端页面。社区可以开发各种自定义前端页面和 Feed 。
它的吸引力在于个人 Canister 的隐私性和自定义的自由。越早部署,随时间积累的内容越多。
本质上这是一个公共发贴空间。该架构是为任何想在去中心化网络上发布内容的人设计的。
这里没有 “ 边界 ” 的概念。它不再是一个孤立的数据岛屿;人们可以自由发布和访问内容。
它的存在超越了任何单个应用程序;它可以代表去中心化互联网上的所有平台。
如果人们想在去中心化网络上发布内容,他们可以选择在像这样的公共空间中进行,而不是在 “ X ” 、“ Reddit ” 或 “ Quora ” 等平台上发布。
这里没有实体控制;内容至上,个人主权至高无上。
思路
首先是有一个可扩展的公共区(Public Area)接收所有用户发的帖子,有一个用户区记录用户注册、个人资料、关注关系。
我们给每位用户创建一个 Feed ,用来存储用户自己的信息流,Feed 也是用户自己的私人空间,用户可以将帖子保存在自己的 Canister 里(Feed),除了自己没人能删除它。
用户与公共区的交互都由 Feed 这个 Canister 自动完成,用户只要查询自己的 Feed 就可以获取关注的最新信息流。发帖、评论、点赞这些交互也都由 Feed 自动完成后面的操作。

用户也可以增加几个高级自定义功能,自己部署一个独立的 Feed 与公共区交互。比如只把帖子点对点发送给某几个 Feed ,建立私密小社交圈子;或者只连接 AI 实现自动发帖等等。任何功能都可以实现,社区可以二次开发,随意拓展各种功能。比如增加一个点对点的私信功能。
消息传输流程
在用户发帖时,Feed 先把帖子存在自己的信息流中,然后把帖子按照粉丝列表点对点依次发给粉丝的 Feed 和公共区的 Bucket 。但是如果有一万个粉丝呢,情况不太好,因为 Canister 之间收发消息受 max input / out queue size 限制,一次性发不了那么多。Feed 得分批次发送很长时间才能发完。
为了增加吞吐量,我们加一个消息中转站:Fetch 。Feed 先把帖子发给公共区,再把帖子 ID 、粉丝发给 Fetch 。Fetch 记录以后,再根据算法依次通知这些粉丝的 Feed 要抓取哪些帖子,最后 Feed 去公共区抓取帖子。
这样即使粉丝很多,也可以在 Fetch 的调节下依次从公共区抓取帖子。
这是一个完全开放的,消息传递稍慢一点的去中心化应用。这种设计为了去中心化牺牲了一点速度,就像比特币一样。
优点是用户的前端只要查询自己的 Feed 就可以获取关注的人的帖子。方便快速,后台的一切由 Canister 之间去中心化协作完成,完全解耦。 几个 Canister 挂掉之后不影响这个系统的继续运行。( Fetch 挂了可以再创建几个)
如果系统暂时无法恢复, Feed 可以点对点直接用 ignore call 分批次给粉丝发送帖子。也就是说,Feed 里内置了两套发贴流程:通过 Fetch 中转站发帖,以及点对点发帖。只是点对点发帖会更慢一点。
好的,说了这么多,现在详细说明一下这种架构吧。
架构
基于 Actor 模型的点对点分布式推送-抓取架构。
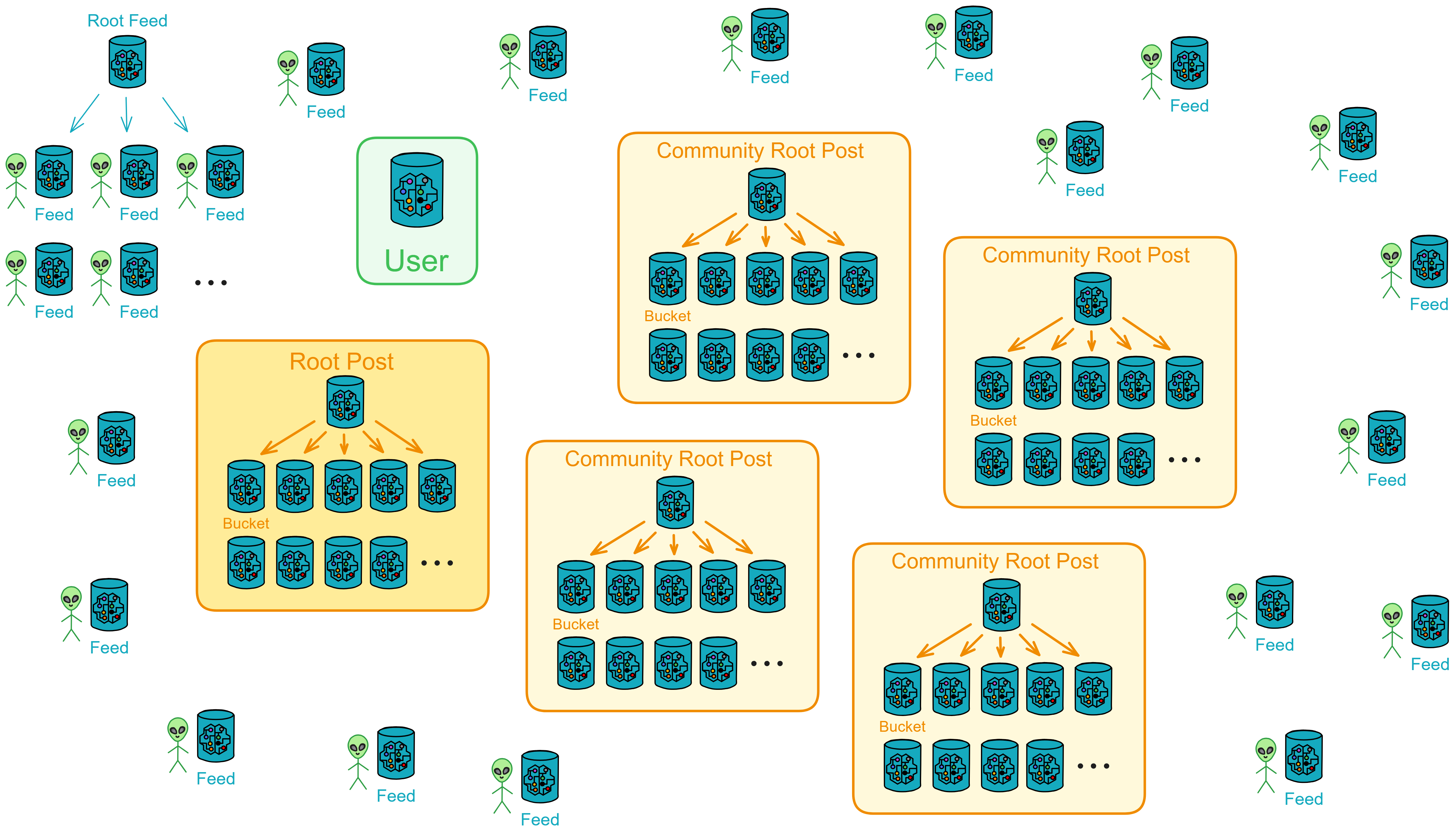
总体上,你可以将 Proton 分为四个模块:User 、Feed 、Post 、Fetch 。
- User :用户区,负责记录用户信息和关系。这里记录了用户的个人资料和关注关系。
- Post :公共区,存储所有公开发布的帖子。Root Post 可以创建许多 Bucket 存储帖子。
- Feed :信息流,存储用户的个人信息流。Root Feed 会为每个用户创建一个 Feed 。
- Fetch :中转站,负责推送某个用户的最新信息流。这里记录了用户的 Feed 未抓取的帖子、评论或点赞。
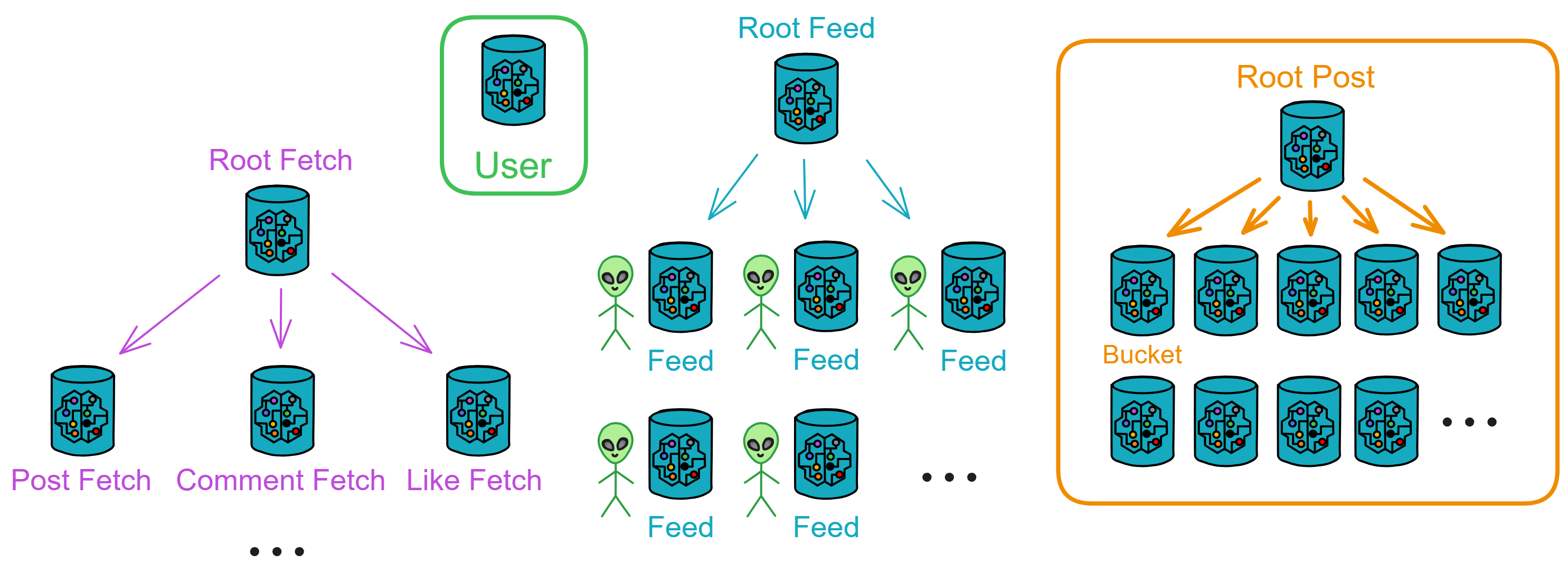
用户可以关注别人(和取消关注),查看公共区最新发布的帖子(所有人发的帖子)、查看自己的信息流(关注的人和自己发的帖子),发帖、转发,评论、点赞、收藏(和取消收藏)。
User
用户区,负责记录用户信息和关系。这里记录了用户的个人资料和关注关系。
User canister 里记录用户的基本信息。比如 UserId 、名称、公司、学校、职业、个人简介、关注关系、自己的 Feed Canister ID 等等。
用户可以调用这里的函数关注某人、更新自己的资料,或者查询自己关注了谁、某人的关注关系。
用户新关注了人或者有新人关注,要通知用户的 Feed 更新列表。
Post
公共区,存储所有公开发布的帖子。Root Post 可以创建许多 Bucket 存储帖子。
Root Post
公共区负责存储所有公开发布的帖子。
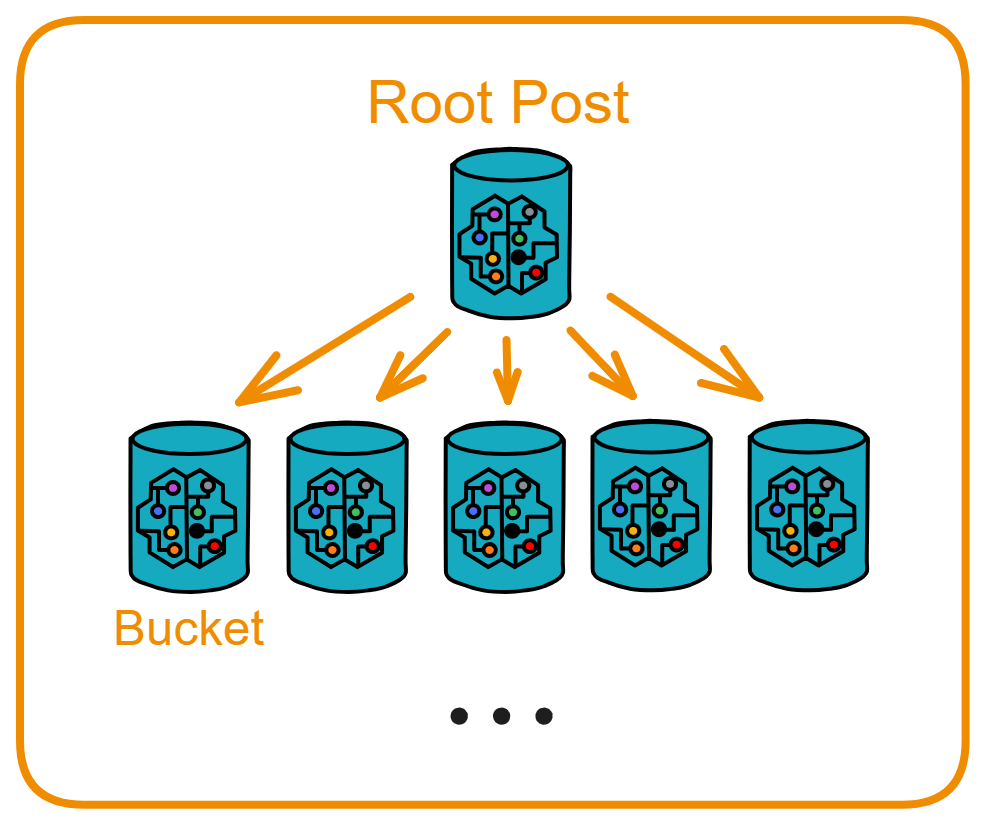
Root Post 可以创建许多 Bucket Canister 来存储帖子。
Root Post 有创建 Bucket 功能、查询可用的 Bucket 是谁、查询所有 Bucket 、查询已存满的 Bucket 。
Root Post 开始先创建 5 个 Bucket 。有一个 Bucket 存满后,再创建一个 Bucket ,始终保持有 5 个可用的 Bucket 。
在用户刚打开前端界面的时候,后台的 Feed 就立刻向 Root Post 去查询可用的 Bucket 是哪个。Root Post 随机返回一个 Bucket ,Feed 里存着一个 “ 可用的 Bucket ” 的变量,查到 Canister ID 之后更新这个变量。
-
调用 Bucket 的查询最新的 5 个帖子,获取公开的最新帖子。
-
当用户向公共区发帖时,调 Bucket 存储帖子。
当某个用户的 Feed 从 Fetch 那里获取到一大堆帖子 ID 后,就可以提供帖子 ID 向 Bucket 查询帖子了。
Bucket
Bucket 可以增查帖子。
其中查询有 3 个函数,分别是查询这个 Canister 一共有多少个帖子、根据 ID 查询某几个帖子(可以传入 7 个 ID 一次性返回 7 个帖子的内容)、查询最新的 n 个帖子(调用时传参告诉它要查最新的多少个帖子)。
精确查询帖子和查询最新的几个帖子时,需要返回帖子本身和目前的点赞、评论数。
Bucket 负责接收帖子、评论、点赞。
Bucket 在接收新帖子时,先看一下帖子 ID 有没有冲突,没冲突才接收。
并把有评论、点赞更新的帖子 ID 通知给 Comment Fetch 、Like Fetch 。
Feed
信息流,存储用户的个人信息流。Root Feed 会为每个用户创建一个 Feed 。
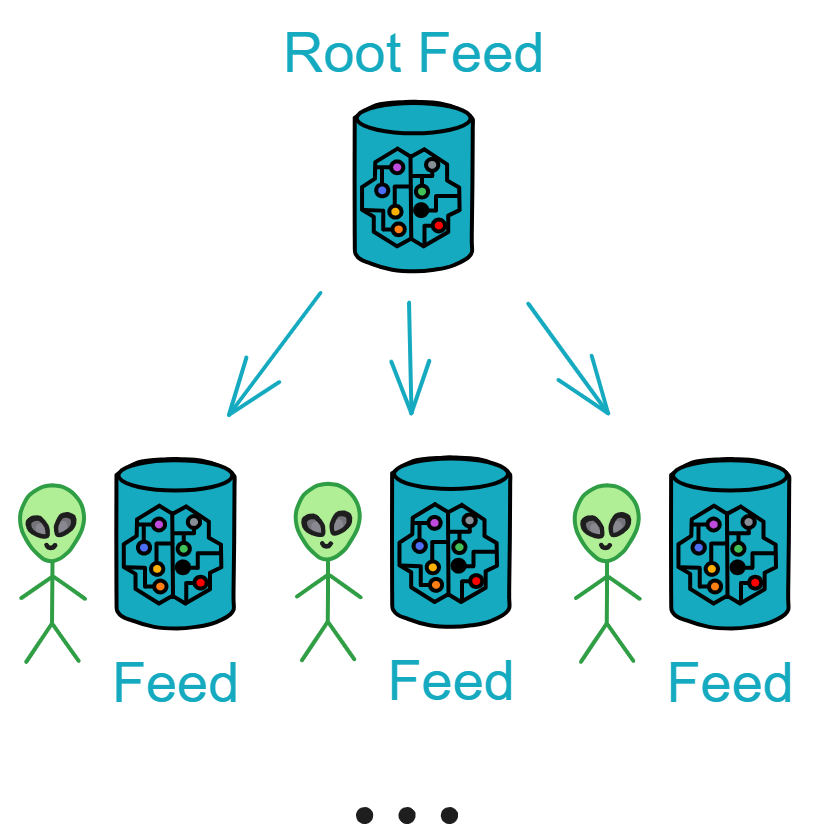
Root Feed
Root Feed 负责给用户创建一个用户自己的 Canister ,并记录总共创建了多少个 Canister 和它们的 Canister ID 是多少。
Feed
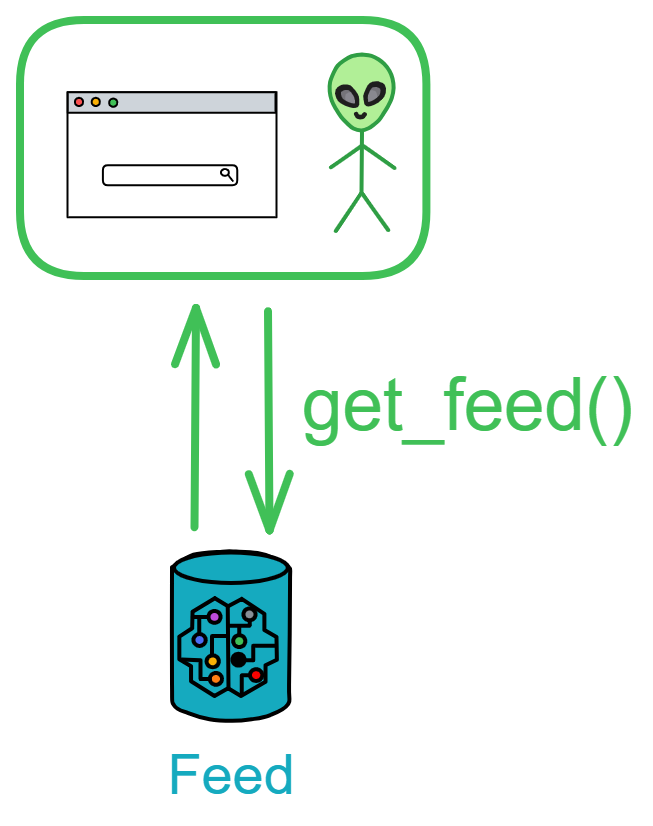
用户通过自己的 Feed 参与 Proton 中的交互:查看、发帖、评论、点赞等等,都通过 Feed 进行。
用户自己的 Feed 里记录着粉丝(用来推送帖子、评论、点赞)、following (接收帖子时检测)、信息流(只保存最新的 3000 个帖子)、保存的帖子(上限是保存 500 个帖子)。
每个帖子都有发布时间、发布者的用户 ID UserId 、帖子 ID PostId 和转发人 ID RepostId (没转发就是空)。
帖子 ID 是 Bucket Canister ID 加 UserId 加自增,这样每个用户都可以直接创建直接的帖子 ID ,不需要与 Bucket 沟通帖子 ID 是什么。
比如 aaaaa-aaa-bbbbb-bbb-1 、aaaaa-aaa-bbbbb-bbb-2 、aaaaa-aaa-bbbbb-bbb-3 ...
查帖:
有 3 个函数可以查询 Feed 里的帖子:查询一共有多少个帖子(统计总数)、根据帖子 ID 查询某个帖子、查询最新的 n 个帖子(调用时传参告诉 Feed 要查最新的多少个帖子)。
发帖:
当用户 A 发布一条新帖子时,前端会发送帖子到用户 A 的 Feed 里。
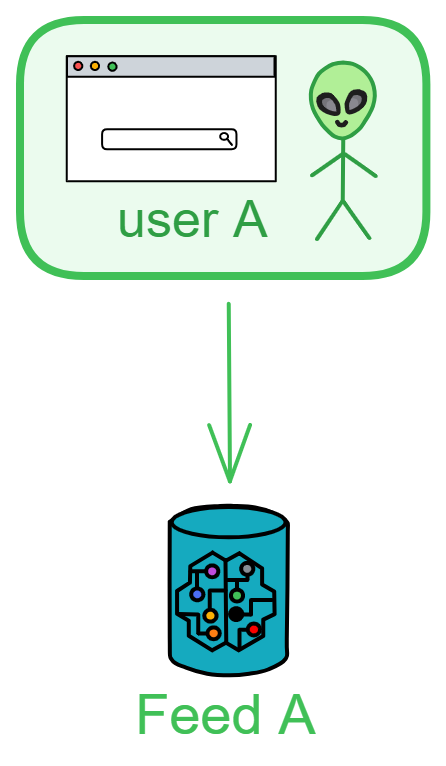
Feed 接收到消息后,会创建一个新帖子存储起来。
然后将帖子内容发送给公共区的 Bucket ,存储到公共区,所有人都能看到。并把发帖人、帖子 ID 、用户 C 、D(粉丝)发送给 Fetch 。
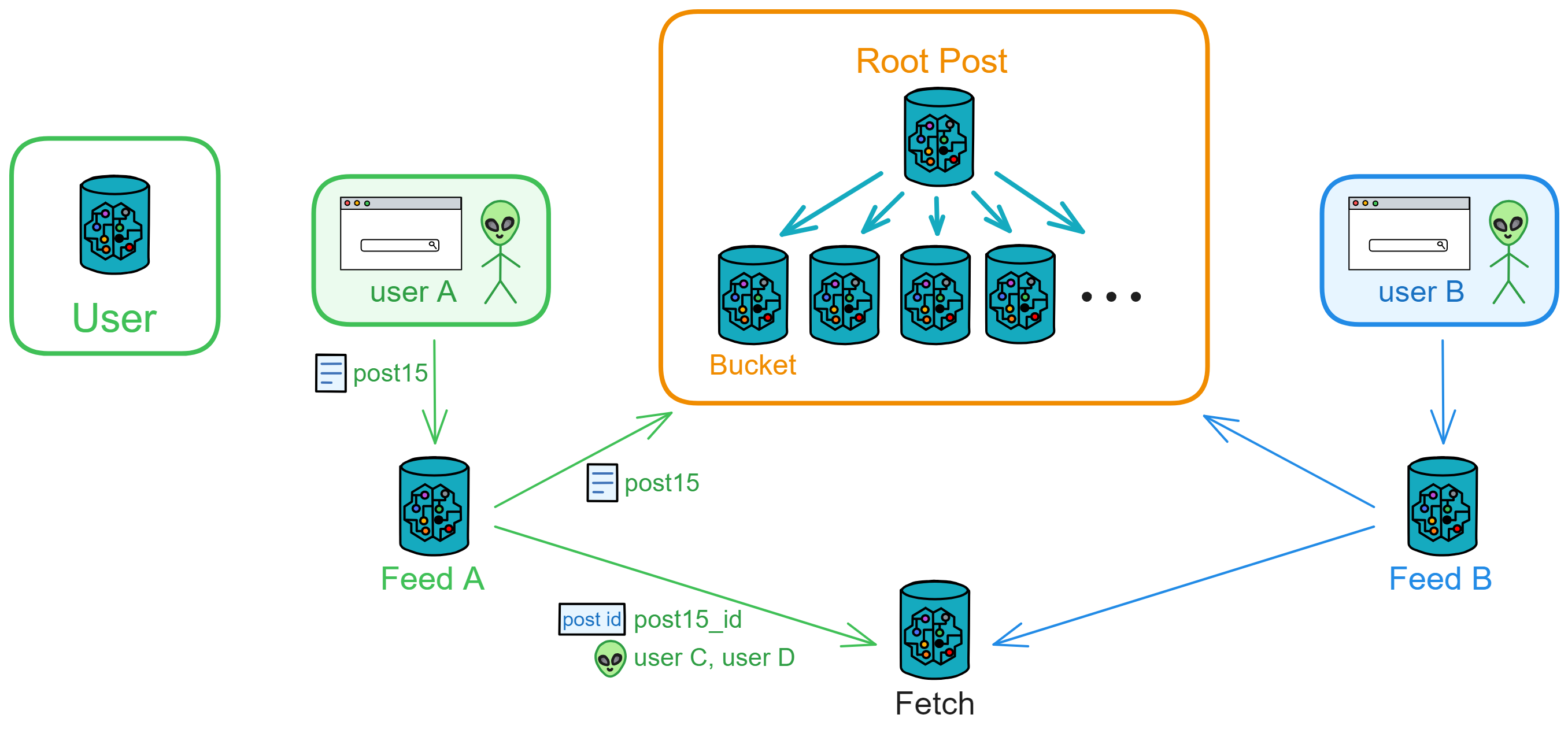
Fetch 会记录下来,并一个个通知用户 C 、D 的 Feed 去根据帖子 ID 抓取内容。Fetch 发出通知之后就删除 user C 和帖子 ID ,Fetch 里存的都是 “ 待通知 ” 的记录。

用户 C 、D 的 Feed 在收到要抓取的帖子 ID 后,会从公共区将对应帖子添加到自己 Feed 的帖子流中。(在这个例子里,用户 C 将收到 ID 为 1 、6 、7 、15 的帖子,用户 C 的 Feed 去 Bucket 里抓取帖子 1 、6 、7 、15 )
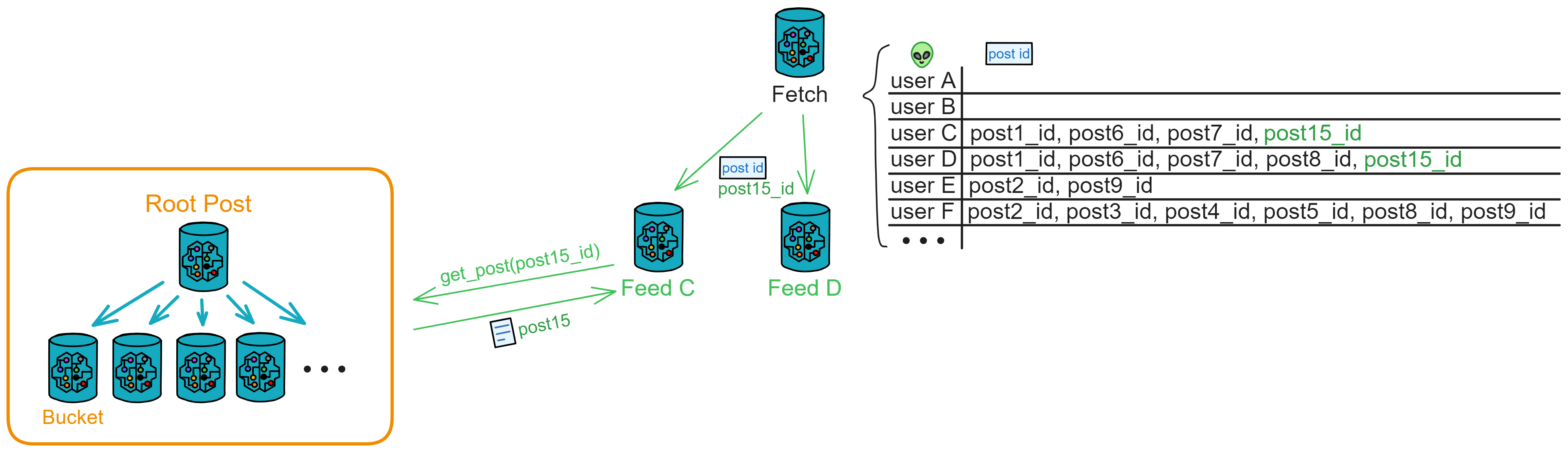
用户 C 、D 打开前端查询自己 Feed 时,就能看见 A 发的新帖子,从而能够在第一时间获取最新的帖子。
如果后来用户 E 关注了用户 A ,那么他的 Feed 只会接收用户 A 的新帖子。
前端只要发送一次请求即可,后续的推送工作(比如通知公共区的操作)都由 Canister 完成。
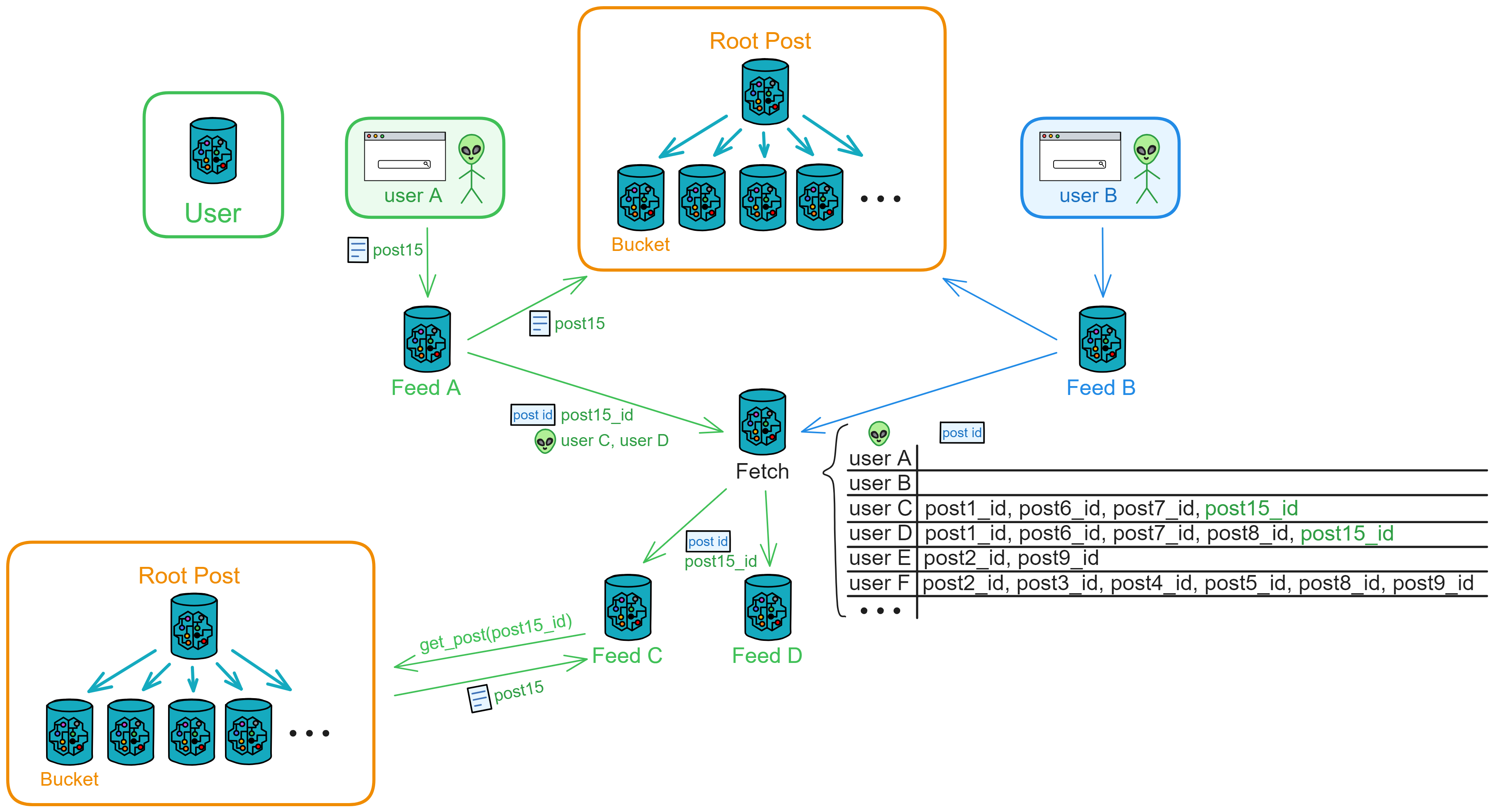
当用户数量增多时,一个 Fetch 可能处理不过来大量发帖请求,这时可以创建一个新的 Fetch 推送消息,可以根据需要水平扩展中转站服务。
删帖:
不可删贴,区块链:一发不可收拾。
不管粉丝的 Feed 里的帖子了,反正只保留最新的 3000 条帖子。(另外,Feed 是人家的私人空间)
转发:
用户 C 把帖子转发给 H 、I 、J 、K : 转发人:C 、帖子 ID :post15_id 、粉丝:用户 H 、I 、J 、K ,发给 Fetch 。
Fetch 记录下来,通知 H 、I 、J 、K 的 Feed 。
这些 Feed 去公共区根据 ID 抓取帖子。
当用户 C 转发帖子时,发布者是用户 A 保持不变,转发人是用户 C 。
评论:
评论流程与发帖流程类似,通过 Comment Fetch 进行评论。
看见帖子的任何人(user X)都可以评论。前端调用 Feed ,传入 post_id 、评论内容。
Feed 收到评论后,先根据帖子 ID 查找自己的 3000 条信息流里有没有这个帖子,有的话就给 Feed 里的这个帖子添加评论。
然后通知公共区的 Bucket 更新评论。
公共区的 Bucket 收到评论之后,Bucket 会通知 Comment Fetch 是哪个帖子有新评论了(帖子 ID )。
Comment Fetch 先去 User 用户区获取发帖人的粉丝是哪些人,没找到这个发帖人就拒绝请求。
然后把帖子 ID 、发帖人和粉丝添加到 “ 待通知 ” 列表里。
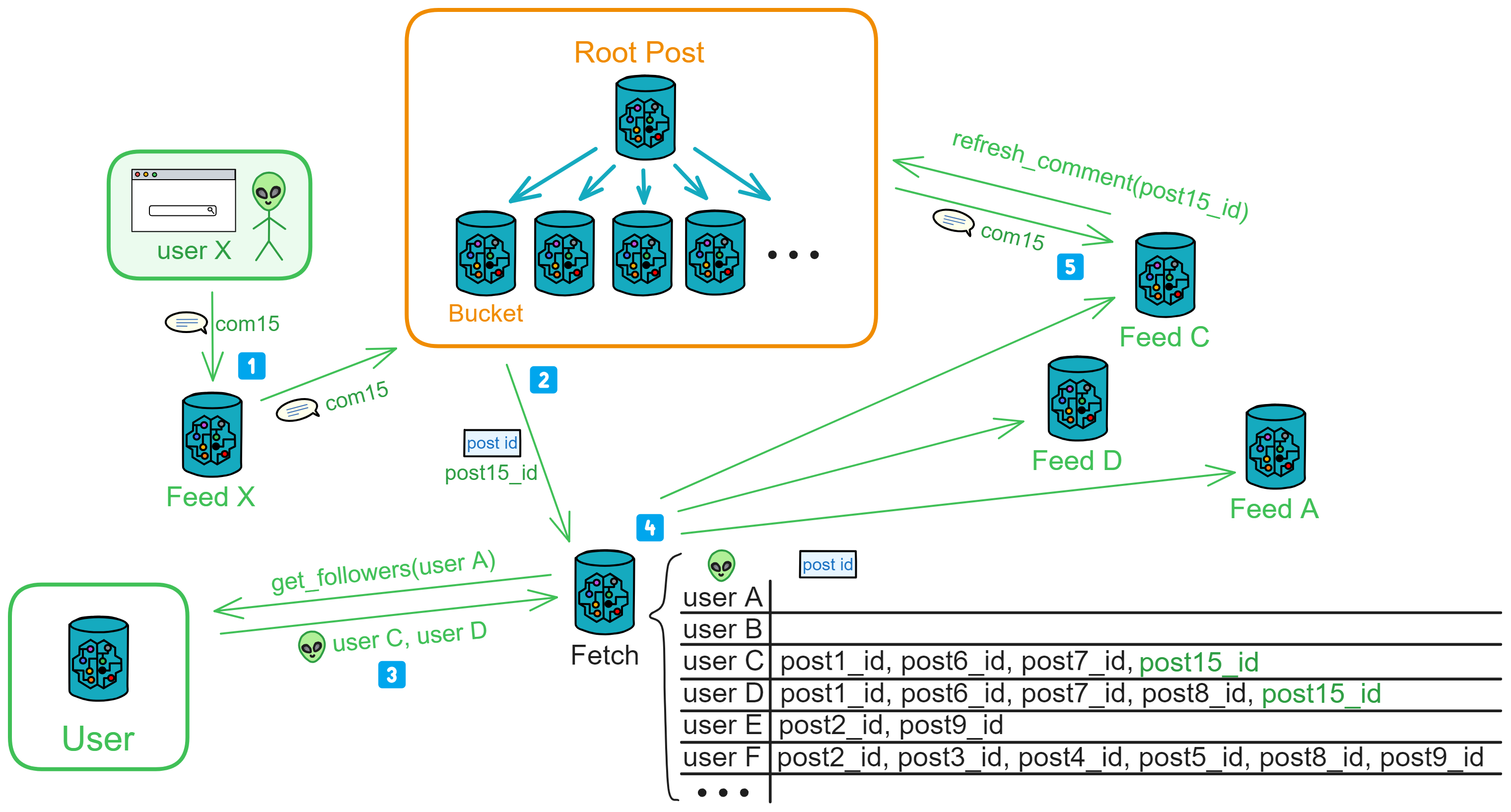
在 Comment Fetch 依次发出通知之后,粉丝根据 Comment Fetch 提供的帖子 ID 去查询帖子的所有评论,把新评论更新到自己的 Feed 里。
如果粉丝 D 转发过这个帖子,D 的 Feed 在收到新评论通知后,会继续向 Comment Fetch 通知:post15_id 、D 的粉丝。
不能删除评论。
点赞:
点赞流程与发帖流程类似,通过点赞 Like Fetch 进行。
看见帖子的任何人(user X)都可以点赞,公共区的 Bucket 收到点赞之后,Bucket 会通知 Like Fetch 是哪个帖子有新点赞了(帖子 ID )。
Like Fetch 先去 User 用户区获取发帖人的粉丝是哪些人,没找到这个发帖人就拒绝请求。
然后把帖子 ID 、发帖人和粉丝添加到 “ 待通知 ” 列表里。
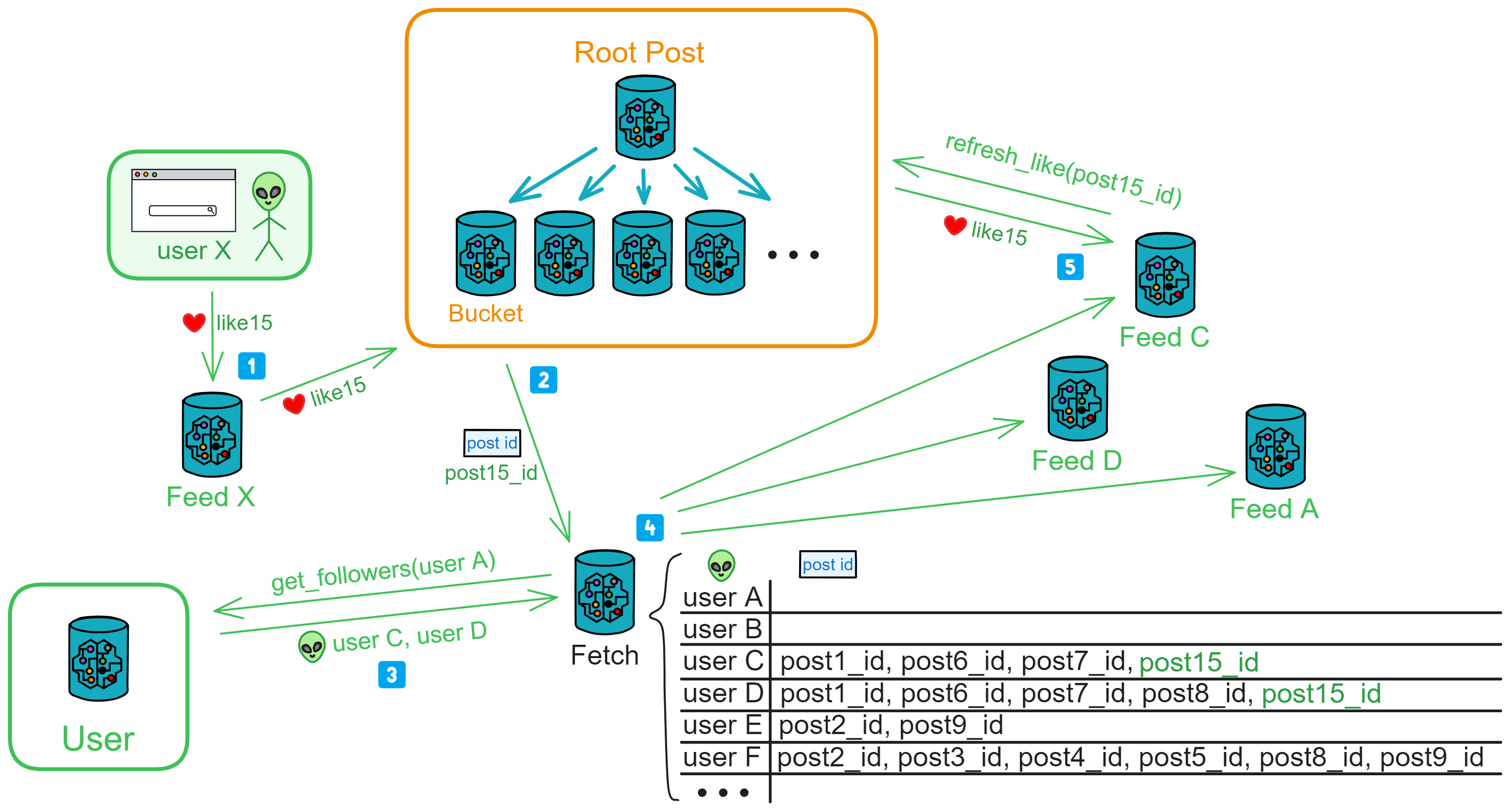
在 Like Fetch 依次发出通知之后,粉丝根据 Like Fetch 提供的帖子 ID 去查询帖子的点赞数,把点赞数更新到自己的 Feed 里。
如果粉丝 D 转发过这个帖子,D 的 Feed 在收到新点赞通知后,会继续向 Comment Fetch 通知:post15_id 、D 的粉丝。
不能删除点赞。
Fetch
负责接收所有人的发帖、评论、点赞消息,并把消息通知给相关的 Feed 。
Root Fetch
Root Fetch 根据用户数量动态创建多个 Fetch 。它可以创建 3 种 Fetch :Post Fetch 、 Like Fetch 、Comment Fetch 。还可以通过 Root Fetch 查询有哪些 Fetch 是可用的。
Post Fetch
接收发帖人的通知:帖子 ID 、发帖人、转发人、粉丝、Cycles 。
内部维护一个通知表:记录每个用户待通知的帖子 ID 有哪些。
根据算法用 ignore call 分批次通知粉丝的 Feed 。
Comment Fetch
接收 Bucket 发的新评论通知:帖子 ID 、发帖人(A)、转发人(空)。
根据发帖人(或转发人)到 User 用户区获取发帖人的粉丝。
内部维护一个通知表:记录每个用户待通知的帖子 ID 有哪些。
根据算法用 ignore call 分批次通知粉丝的 Feed 。
如果某个粉丝 C 转发过这个帖子,C 的 Feed 在收到新评论通知后,会继续向 Comment Fetch 发送通知:帖子 ID 、发帖人(A)、转发人(C)。
Like Fetch
接收 Bucket 发的新点赞通知:帖子 ID 、发帖人(A)、转发人(空)。
根据发帖人(或转发人)到 User 用户区获取发帖人的粉丝。
内部维护一个通知表:记录每个用户待通知的帖子 ID 有哪些。
根据算法用 ignore call 分批次通知粉丝的 Feed 。
如果某个粉丝 C 转发过这个帖子,C 的 Feed 在收到新点赞通知后,会继续向 Like Fetch 发送通知:帖子 ID 、发帖人(A)、转发人(C)。
以上的 User 、Post 、Fetch 、Feed 构成了 Proton 的基础架构。
在这个架构基础上,我们可以想象一下模块化 Actor 模型带来的更多优势 ...
一切都由用户自己选择
用户可以选择通过 Feed 点对点私密发送帖子给某几个粉丝的 Feed ,而不公开发布。
用户也可以建立自己的 “ 社区服务器 ” ,就是一个自己控制的社区公共区。这样人们的 Feed 可以订阅这个社区服务区,Feed 每隔 2 小时向社区服务器请求更新信息。Feed 里保存着上一次更新的 post id ,Feed 请求时,传入上一次的 post id ,社区服务器就会找出自上一次更新的帖子返回给 Feed 。
整个系统都是模块化的,都可以由社区去自发地构建。比如用户可以建立自己的一个社区服务器、广播矩阵等等。(广播矩阵后面介绍)
自动调节压力
Fetch 累积了一定的消息之后,通过算法调整通知的顺序和间隔(先通知哪个 Feed 和每通知几个 Feed 之后间隔多少毫秒再通知其他 Feed ),保证公共区的查询压力不能太高。Feed 在收到通知后,如果抓取失败,应该等 20 秒再抓取。
如果公共区面临的查询压力太大,就会告诉 Root Fetch :“ 慢一点通知 Feed ” ,Root Fetch 会通知它下面的几个 Fetch 减小通知频率。如果 10 分钟后压力依然很大,Root Post 也可以再创建一个 Bucket ,让新帖子发到新 Bucket 里。
而且如果用户增多以后,Fetch 本身也可以根据需要增添。
因为只要 Feed 发送一条信息,Fetch 就得通知很多个其他的 Feed 。这样开放的环境中,很容易造成 Dos 攻击。所以在 Feed 把信息发给 Fetch 时,需要交一笔 Gas 费,收到 Gas 费之后 Fetch 才会把信息放进 “ 待通知 ” 列表。
广播矩阵
假如有 1000 个人在 2 分钟内对帖子 15 点赞,Fetch 仍然只需要通知帖子 15 的粉丝一次就可以。然后这些粉丝自己去公共区的 Bucket 里查现在到底有多少个点赞。
当然,Fetch 也可以记录下来哪个帖子有多少个点赞、该通知谁,积累一定时间之后,然后直接通知粉丝的 Feed :某个帖子有 1000 个点赞。这样 Feed 就不需要去 Bucket 里查点赞数了,Fetch 里都记录好了。
但是这样也更中心化,所有 Feed 都听 Fetch 的指挥,直接相信 Fetch 给的点赞数。如果 Fetch 被控制,就有可能出现虚假的点赞数,所以让 Feed 自己去 Bucket 里查才是最真实的。
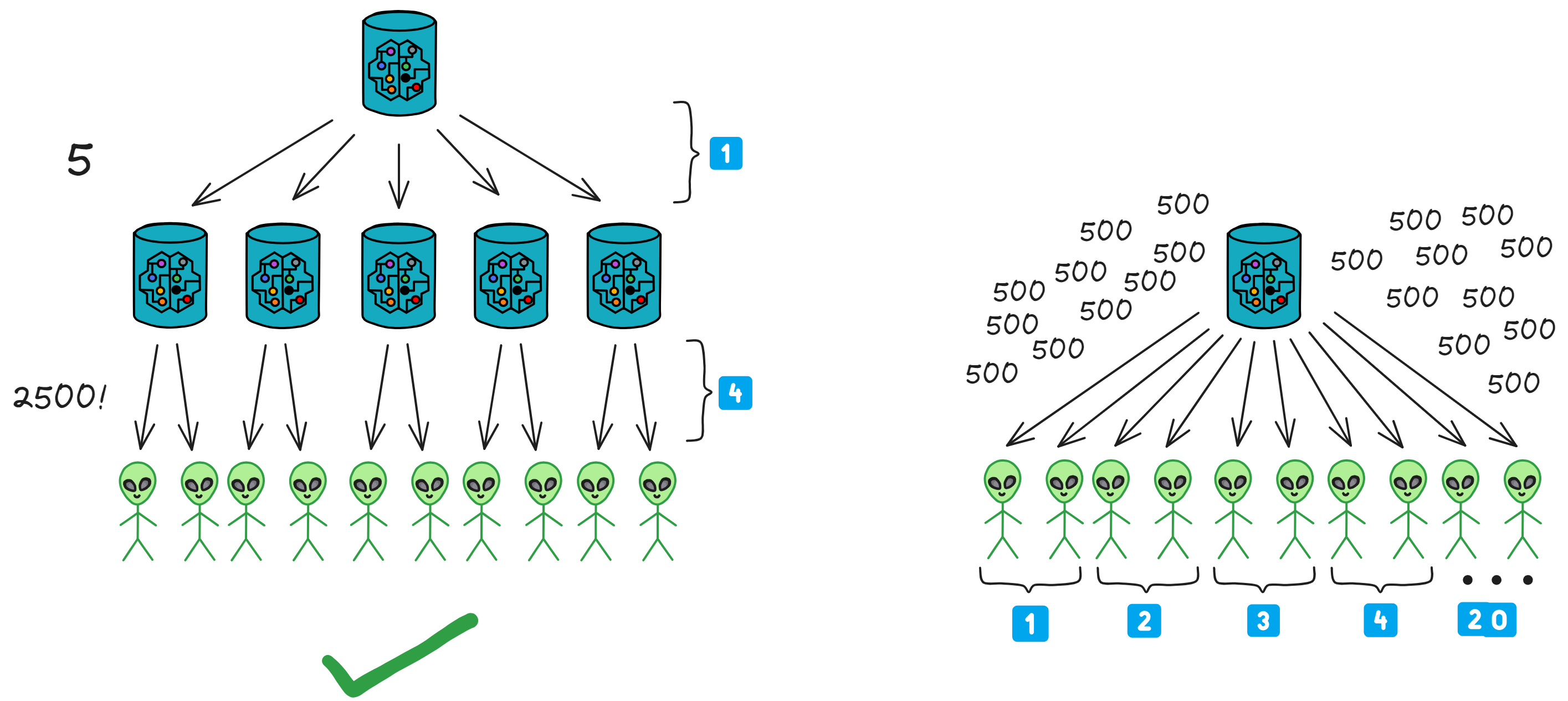
现在我们来想想高并发的场景:假 如 Fetch 要通知 1 万个 Feed ,但是由于 Canister 系统的消息队列限制,假设一个 Fetch 一次只能向 500 个 Feed 发送通知。
如果只有一个 Fetch 工作,需要 20 次才能通知完。这时就需要多个 Fetch 协作了。
一个 Fetch 先把要通知的用户列表分成 5 份,然后分发给 5 个 Fetch ,这样一次性就可以发送 2500 个通知,只要 4 次即可完成推送!
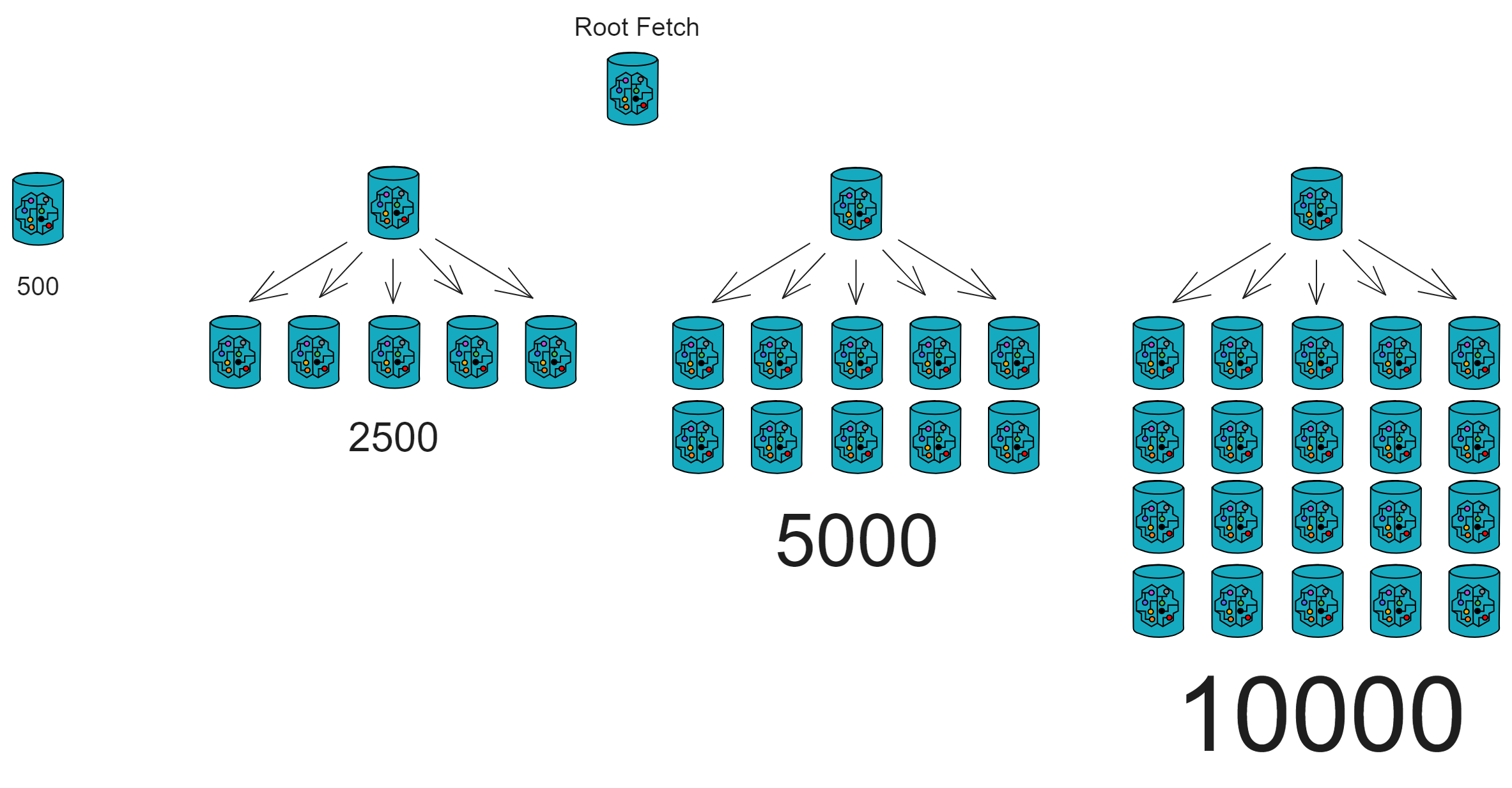
Canister 的消息输出队列是 500 ,所以我们可以建立不同发送能力的中转站:500 ,2500 ,5000 ,10000 ...
一个 Canister 一次可以发送 500 个消息,五个 Canister 一次可以发送 2500 个消息,十个 Canister 一次可以发送 5000 个消息,二十个 Canister 一次可以发送 10000 个消息。
保险起见,实际使用时,我们应该留出一部分消息输出,保证其他通信正常以及紧急情况时呼叫联系 Root Fetch 的消息输出,所以应该设置一个 Fetch 一次最多发送 430 条通知。
为了防止 Dos 攻击,用户每次发帖、评论、点赞时,应该同时发送一些 Cycles 才行。使用不同种类的广播矩阵收费也不同。
如果某个人的粉丝特别多,他也可以选择不相信别人任何人,自己建立一个私人广播矩阵。用作专门给自己的粉丝通知消息。
不过这些是未来的规划,现在我们先把大框架设计好,有了基本功能之后再持续优化细节。
规划
最终规划:模块化、公共数据库、用户云终端。
模块化:将 Canister 按照功能分类,各司其职。
公共数据库:开放的数据库,任何人都可以直接发布和获取内容。
用户云终端:每个用户有自己的独立服务器(Canister),提供链上私人服务。
做
这是一个复杂、庞大的大型应用。
在这个教程中,我们将使用 Motoko 构建这个 DApp 的基础功能。
🆗 Let’s go! 🆗
